


IV. Présentation du projet▲
IV-A. Spécifications du projet▲
Ce projet permet d'importer dans Alfresco une arborescence de documents numérisés et organisés dans un répertoire sur système de fichier. Moyennant quelques configurations (le chemin du plan de classement à importer, c'est-à-dire le dossier de documents, et les paramètres d'accès au serveur GED Alfresco : URL, Login, Mot de passe), le projet s'exécute entièrement dans l'environnement TOS de Talend ou à l'extérieur. Le projet consiste en un agencement de composants Talend au sein de Jobs réalisant des fonctions contribuant à l'intégration des documents dans l'entrepôt qui à priori est distant. Cet article montre non seulement comment utiliser le projet ou le customiser pour des cas plus spécifiques mais fera également une présentation détaillée de ces briques internes.
IV-B. Les Outils▲
La réalisation de ce projet a nécessité les outils suivants :
- Alfresco version communautaire 2.9.0. Les binaires d'Alfresco sont téléchargeables iciDownload_Alfresco_Community_Network. Il est possible d'utiliser une version plus évoluée;
- JBoss 4.2.0 : inclus dans l'installeur Alfresco;
- Talend Open Studio 3.1 Téléchargeable ici.
IV-C. Architecture de la solution ▲
Ci-dessous l'architecture macroscopique de la solution dans un environnement d'intégration.
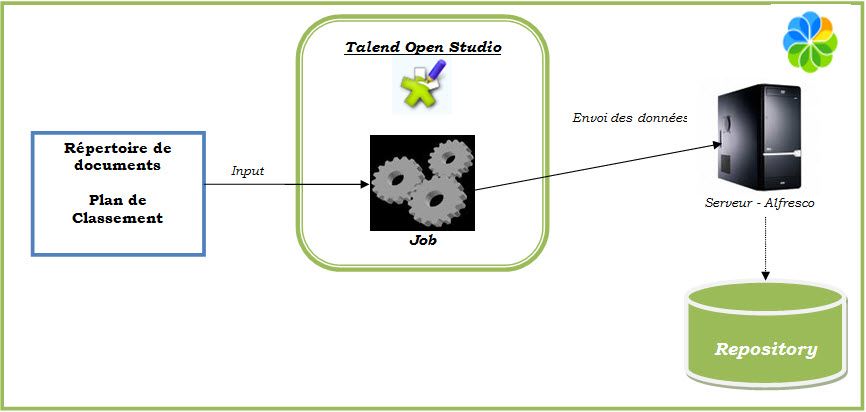
Le Job Talend prend en entrée le chemin (path) du répertoire de documents ou du plan de classement à importer. A la suite d'un certain nombre de transformations et de traitements, le job consomme un service distant Alfresco pour l'envoi des informations. Le serveur Alfresco enregistre par la suite les documents et le plan de classement dans l'entrepôt (repository).
Nous allons nous intéresser dans la section suivante à comment construire méthodiquement notre job par agencement de composants, de façon à satisfaire ce besoin.
IV-D. Méthodologie▲
Pour permettre l'intégration de toute l'arborescence d'un dossier du système de fichiers (tout son contenu inclus) dans Alfresco, uniquement à partir du chemin absolu du dossier à importer, le Job est décomposé en deux phases.
La première phase consiste à générer un plan de classement correspondant à l'organisation des documents à importer. Ce plan de classement est généralement identique à la structure du dossier de documents à importer. Cette première phase produit en sortie un fichier XML de description du plan de classement. Elle prend en entrée, un fichier XML décrivant les répertoires de documents à importer ainsi que les paramètres de connexion au serveur de GED distant.
La deuxième phase repose sur le composant tAlfrescoOutput. Celui-ci prend en input le plan de classement produit en phase 1, s'appuie sur une configuration de mapping des propriétés des documents entrants avec un modèle de contenu du serveur de GED. Cette seconde étape (intitulée chargement) réalise l'opération de chargement du plan de classement généré à la première étape dans Alfresco.
A chacune de ces phases, nous associons un job Talend respectivement XMLContentHierarchyGenerator et LoadXMLContentHierarchyIntoAlfresco. deux jobs seront orchestrés par un troisième nommé Orchestrator. La section suivante décrit la mise en place de ces jobs et leurs agencements.
IV-E. Design des jobs▲
La solution est composée de 3 jobs, dont l'un joue le rôle d'orchestrateur pour les deux autres. Nous allons tout d'abord présenter le job d'orchestration.
IV-E-1. Orchestrateur « Job Orchestrator »▲
La figure 2 montre le design de l'orchestrateur. Ce job d'orchestration réalise l'interface entre les deux phases décrites ci-dessus. Ce job crée un flow de traitement de répertoires de documents à importer un à un de façon itérative. Il prend en entrée, à travers le composant tFileInputXML_1 le fichier de description des dossiers de documents à importer (il peut de ce fait importer plusieurs dossiers de documents à la fois) présents sur le disque. Pour chaque dossier, il crée une itération (traitement du composant tFlowToIterate_1) qui est soumise au Job XMLContentHierarchyGenerator (de lanceur tRGenerateXMLContentHierachy sur la figure). Le Job XMLContentHierarchyGenerator réalise la phase 1 c'est-à-dire la génération d'un fichier XML fournissant le plan de classement des documents importés dans le dossier.
Chaque plan de classement est véhiculé au second Job LoadXMLContentHierarchyIntoAlfresco (de lanceur tRJalfrescoXMLImporter) qui réalise la deuxième phase d'exécution c'est-à-dire l'intégration des fichiers et la création de l'arborescence dans le serveur Alfresco distant.

La figure 3 présente un exemple de fichier XML de description des dossiers à importer et les paramètres de connexion au serveur distant. Il s'agit du fichier XML d'entrée sur le premier composant tFileInputXML_1 de l'orchestrateur.
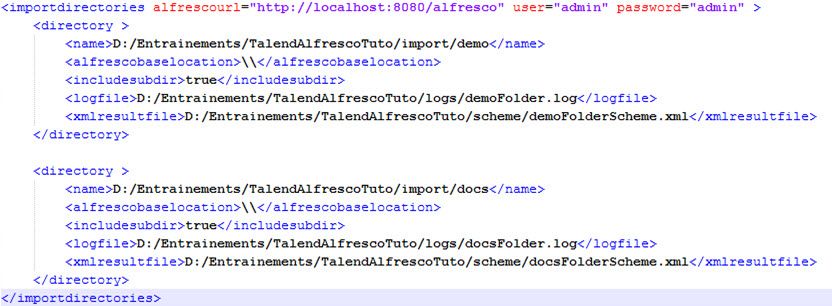
L'élément racine du fichier de description porte le nom importdirectories. L'attribut alfrescourl représente l'URL du serveur Alfresco, user représente un login et password le mot de passe pour se connecter au serveur. Les sous-éléments directory décrivent les dossiers de documents à importer du disque.
Un répertoire à importer comporte les attributs :
- name : le nom complet du répertoire sur le système de fichier;
- alfrescobaselocation : répertoire de base dans Alfresco à l'intérieur duquel le dossier doit être importé;
- includesubdir : indique si oui ou non le dossier doit être importé conjointement avec ses sous répertoire : par défaut il est à True et le cas false n'a pas été pris en compte dans cette version;
- logfile indique le fichier à l'intérieur duquel seront persistés les logs relatifs à l'importation du dossier;
- xmlresultfile : fichier résultat intermédiaire ; c'est à l'intérieur de ce fichier que le plan de classement résultant pour le dossier de l'itération courante sera sauvegardé.
On peut voir que ce fichier déclare l'importation de deux répertoires sur disque : le répertoire de documents demo situé sur le disque à D:/Entrainements/TalendAlfrescoTuto/import/demo et le répertoire de documents " docs " situé sur le disque à D:/Entrainements/TalendAlfrescoTuto/import/docs.
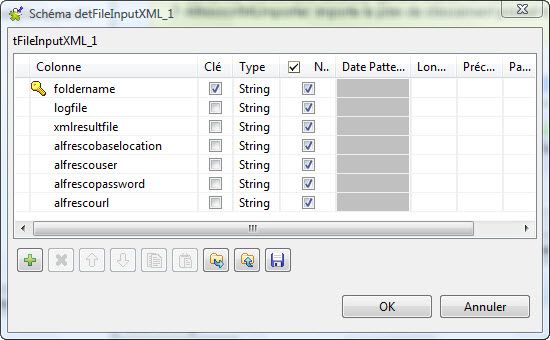
Ce fichier doit impérativement respecter le schéma décrit dans l'environnement TOS. Pour accéder au schéma, il suffit de cliquer sur le composant tFileInputXML puis sur le bouton " Editer le schéma " (figure ci-dessous). Le fichier est contrôlé lors du runtime.
IV-E-2. Génération du plan de classement « Job XMLContentHierarchyGenerator»▲
Ce Job réalise la première phase de l'exécution qui est la production des plans de classement des dossiers de documents importés (éléments directory du fichier input) de façon itérative. Il est invoqué par l'orchestrateur à la sortir du composant tFlowToIterate_1 dont le rôle est de sortir les éléments du flow (les dossiers) de façon itérative.
Pour rappel, le composant tFileInputXML de Talend permet de lire un fichier XML qu'il reçoit en entrée. En s'appuyant sur des expressions XPath, on produit un flow de données qui est régi par le schéma qui lui est assigné. La valeur de chacune des colonnes du schéma étant approvisionnée par le résultat de l'évaluation d'une expression XPath. La figure 5 montre l'interface de configuration du composant.
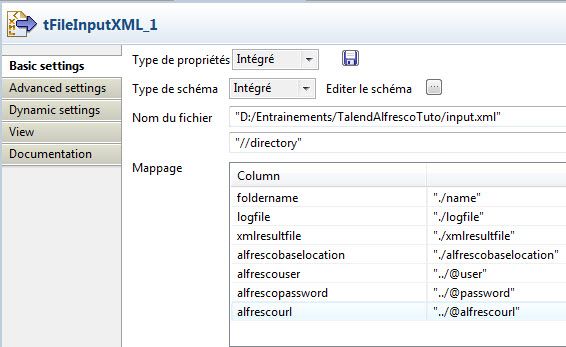
L'élément de boucle dans le fichier XML d'entrée est le dossier ; ceci est matérialisé par la balise directory et accessible en XPath par l'expression "//directrory". A partir de la balise directory, l'attribut "foldername" que nous créons pour stocker le nom du répertoire peut être obtenu par l'expression "./name". Idem pour tous les autres éléments internes à la balise directory. Par contre, il faut remonter à la balise parente afin de retrouver la valeur des attributs tels qu "user", "password", "alfrescourl".alfrescouser =''../@user''. Pour plus d'informations sur XPATH voir.
Le composant tFlowToIterate a un comportement basique qui consiste à reproduire intégralement le flow en entrée en une itération sur la sortie.
Mais quelle transformation opère concrètement le Job XMLContentHierarchyGenerator?
Il prend en entrée trois paramètres de type chaîne de caractères. Cliquez sur le Job. L'interface de paramétrage du Job s'affiche, figure 7.
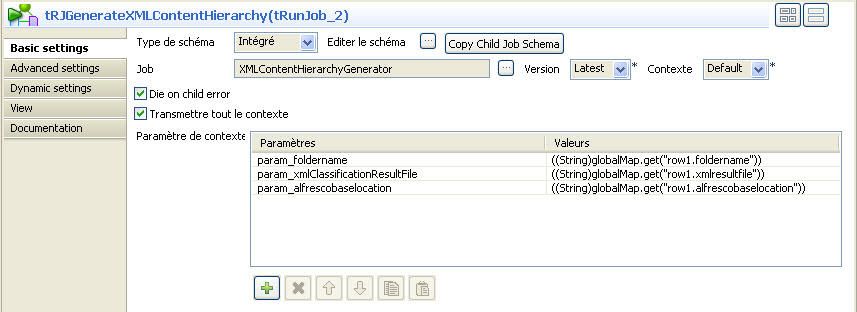
Ces trois paramètres (param_foldername, param_xmlresultfile et param_alfrescobaselocation) sont issus du flow de données de l'itération injectée par tFlowToIterate_1. Autrement dit, du flow de données relatif à un dossier c'est-à-dire un élément directory du fichier input qui est relié à l'itérateur par le flow row1. Le Job Orchestrateur est chargé de la fourniture des paramètres effectifs d'appel.
- param_foldername : le nom du dossier pour lequel on souhaite générer un plan de classement;
- param_xmlClassificationResultFile : le chemin complet où sera crée le fichier XML qui contiendra le plan de classement à générer;
- param_alfrescobaselocation : le chemin de base dans Alfresco, où le dossier param_foldername sera importé.
Le job XMLContentHierarchyGenerator s'exécutera et produira un plan de classement correspondant au répertoire de documents importés à l'emplacement spécifié par param_xmlClassificationResultFile.
La figure 8 montre un exemple de plan de classement généré par le Job.
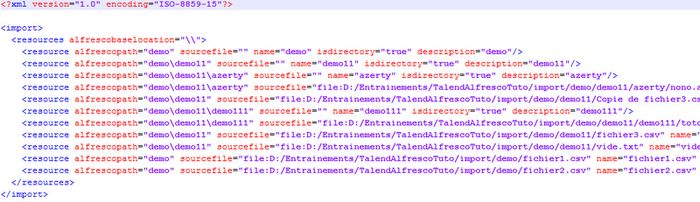
Un dossier importé correspond à une balise ressources. Chaque contenu du dossier (fichiers et sous-dossiers) est une ressource du dossier matérialisé par la sous balise ressource. Une ressource est définie par :
- alfrescopath : Répertoire de base dans Alfresco à l'intérieur duquel le dossier doit être importé ;
- sourcefile : vide si la ressource est un dossier, mais représente le chemin absolu du fichier sur le disque si la ressource est un fichier ;
- name : nom de la ressource. C'est le nom qui sera donné au contenu enregistré dans Alfresco. Il s'agit du nom du fichier ou du dossier importé ;
- isdirectory : false si la ressource est un fichier et true si c'est un dossier ;
- description : la description de la ressource.
Ces informations sont nécessaires et suffisantes pour importer le dossier dans le repository distant Alfresco.
Le Job génère un fichier de description de plan de classement par dossier importé. Le descripteur porte le nom du dossier importé. Vous pouvez retrouver les descripteurs des répertoires importés dans le dossier " import " du projet. Le descripteur de la figure 8 correspond au dossier de la figure 9.
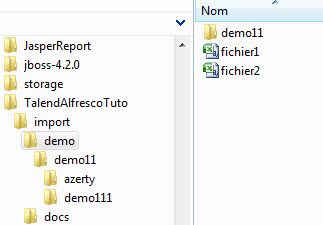
Rappelons que par plan de classement, nous désignons l'ensemble des données à passer au Job de la seconde phase afin de recréer intégralement dans Alfresco la structure d'un dossier du système de fichier. Ce plan de classement est étroitement lié au contenu à mapper.
Nous n'avons toujours pas montré comment sont agencés les composants du Job. La figure 10 présente l'agencement des composants du Job.
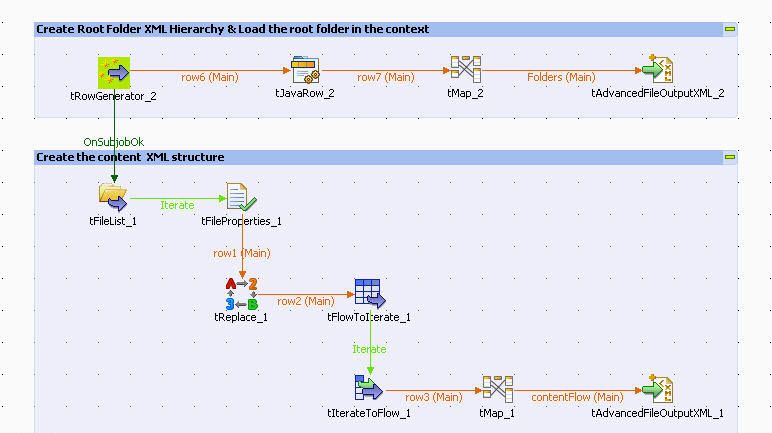
Le job XMLContentHierarchyGenerator produit pour chacune des lignes en entrée (chaque répertoire de documents numériques à importer) qu'il reçoit un plan de classement XML. Le design du job est composé de deux branches dépendantes.
La première qui va du tRowGenerator_2 vers le tAdvancedFileOutputXML_2 et la seconde qui va de tRowGenerator_2 à tAdvancedFileOutputXML_1.
La première a pour mission de créer la structure du fichier XML du plan de classement en se limitant au répertoire racine contenant les documents à importer, sans toutefois entrer dans son organisation interne. La deuxième branche complète ce fichier XML en itérant sur les fichiers et sous-dossiers du répertoire racine.
Chaque répertoire de documents importé est identifié dans le modèle d'entrée par l'élément name sauvegardé dans le contexte d'exécution avant le lancement du Job dans le paramètre context.param_foldername dont la valeur est le chemin absolu du répertoire de documents à importer sur le système de fichiers.
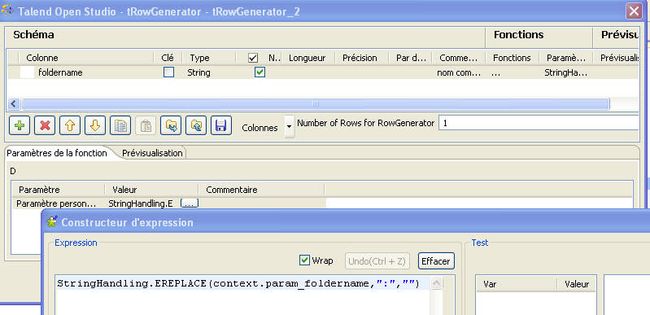
Le composant tRowGenerator_2 va faire un traitement sur la valeur de ce paramètre. Rappelons que ce paramètre est le chemin absolu au format du système d'exploitation du répertoire racine de documents à importer (en l'occurrence celui du système de fichiers de Windows). Le traitement consiste en retirer le caractère ":" placé après la lettre du lecteur dans le chemin absolu. L'expression exécutée pour cette transformation est :
StringHandling.EREPLACE(context.param_foldername,":","")
La figure 11 montre la saisie de cette expression dans le TOS. La fenêtre s'ouvre en double-cliquant sur le composant.
La résultante est placée dans un schéma (row6) à une colonne (foldername) et envoyée au composant tJavaRow_2.
Le composant tJavaRow_2 extrait le nom du répertoire racine de documents à importer et le sauvegarde dans le contexte d'exécution. La figure 12 montre le code java exécuté par le composant pour réaliser cette transformation.
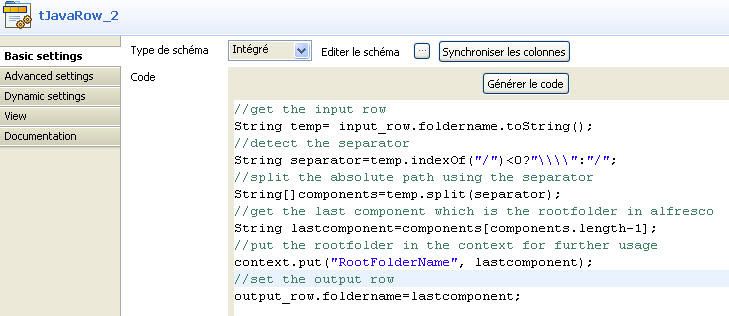
Il détecte premièrement le séparateur utilisé (/ ou \). Puis par le biais des fonctions String.split, il découpe les tokens et extrait le dernier qui est le nom du répertoire à importer. Il le place dans le contexte d'exécution.
L'idée ici est de produire un path exploitable pour l'enregistrement dans le repository de documents Alfresco. Le tableau suivant donne quelques exemples.
| Dossiser à importer | AlfrescoBaseLocation | LastFolderName | RootFolderAlfresco |
|---|---|---|---|
| C:\Toto\Tata\Titi | \\ | Titi | \\Titi |
| C:\Toto\Tata\Titi | \\dossiers_administratifs | Titi | \\ dossiers_administratifs \Titi |
| D: | \\personnels\dossiers_retraite | D | \\personnels\dossiers_retraite\D |
Le tableau montre la logique. Le path où seront enregistrés les documents importés (RootFolderAlfresco) est formé à partir du chemin relatif (AlfrescoBaseLocation) et du nom du répertoire.
Le flow d'exécution continue sur le composant tMap_2 (figure 13). Il crée un schéma à trois colonnes :
- foldername : dans laquelle il copie la valeur de l'unique colonne d'entrée (foldername) qui contient le nom du répertoire de documents à importer;
- sourcefile : chaîne de caractère vide pour les ressources dossier;
- absolutepath : chemin absolu dans le repository Alfresco.
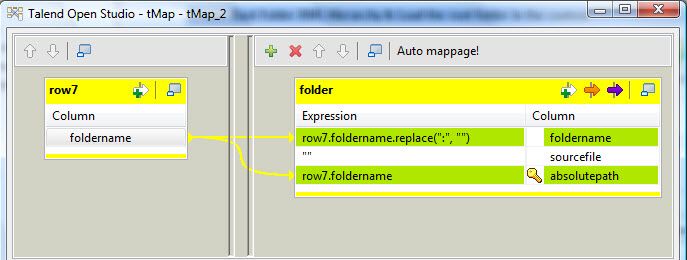
Le schéma, nommé "folder" est envoyé au composant tAdvancedFileOutputXML_2.
La donnée est véhiculée au composant tAdvancedFileOutputXML_2 (figure 14).
Le tAdvanceFileOutputXML_2 produit le fichier XML de sortie (première structure de la structure de classement) à la sortie indiquée dans sa configuration en suivant le mapping de la figure. La figure 14 montre l'interface de configuration du composant.
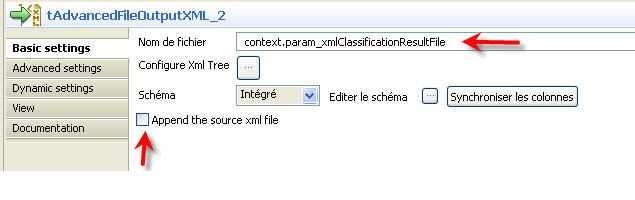
- Nom de fichier : indique l'endroit où sera crée le fichier. Cette information se trouve dans le paramètre context.param_xmlClassificationResultFile;
- Configure Xml Tree : ouvre l'interface de mapping ci-dessous. Il permet de créer la structure XML dans laquelle seront chargées les données mappées;
- Schéma : la valeur intégré indique que le schéma va être crée dynamiquement, c'est-à-dire en se basant sur le mapping;
- Editer le schéma : inutile du moment que l'option schéma intégré est activée;
- Append the source xml file : indique que le contenu du fichier XML de sortie doit être vidé s'il existe déjà.
Le mapping effectué est présenté dans la figure 15.
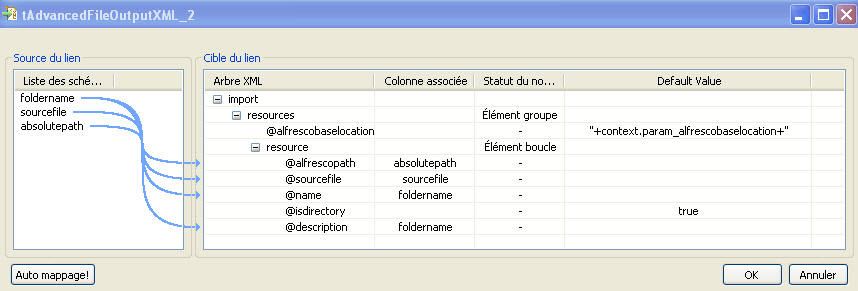
Le composant crée l'élément racine import et un sous élément resources. Il crée une première ressource resource pour le répertoire racine des documents à importer. Une ressource, qui est soit un dossier, soit un fichier sera composée de 5 informations :
- @alfrescopath : le chemin absolu de la ressource dans l'arborescence du repository Alfresco ;
- @sourcefile : le chemin absolu sur le système de fichier si la ressource est un fichier et nulle si la ressource est un dossier ;
- @name : le nom du fichier ou du dossier ;
- @isdirectory : true si la ressource est un dossier et false sinon ;
- @description : la description de la ressource.
Ces informations sont en fait des attributs de l'élément resource.
La colonne "foldername" sera mappée aux attributs "name" et "description", la colonne "sourcefile" est mappé à l'attribut "sourcefile", "absolutepath" à l'attribut "alfrescopath".
Remarque : l'information @alfrescobaselocation, attribut de l'élément resources qui représente le chemin relatif à l'arborescence du repository Alfresco sous lequel seront stockés les documents importés sera traité lors du lancement du second Job.
Rendu à ce stade, la première branche du Job a crée le fichier XML du plan de classement des documents, mais de façon partielle car elle ne décrit que le répertoire racine des documents à importer. La seconde branche va être exécutée. Son rôle sera de parcourir le répertoire de documents à importer et de compléter le fichier XML.
Le premier composant de la deuxième branche est le composant tFileList. Le rôle de ce composant est de lister tous les fichiers et sous-dossiers contenus dans le répertoire de documents importés. Comme on peut le deviner, il prend en entrée le chemin du répertoire à lister. Cette information est contenue dans le paramètre context.param_foldername qui est fournit dans la configuration du composant (voir figure 16).
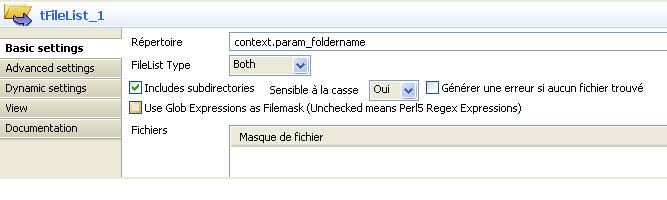
Le composant va passer de façon itérative les éléments de sa liste au composant tFileProperties_1. Ces éléments ne sont autres que les fichiers et sous-dossiers du répertoire, dans un ordre hiérarchique respectant l'ordre d'apparition des répertoires. Le composant inclut des options permettant de faire lister de façon récursive les sous dossiers et de sélectionner le type de contenu à lister (File, Directories, Both).
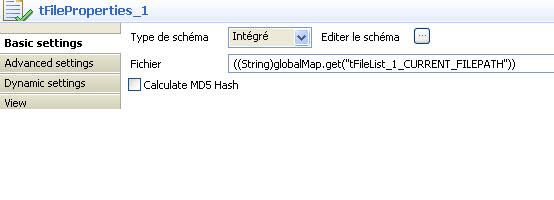
Le composant tFileProperties_1 fournit les propriétés du fichier qui lui est passé en entrée : taille, chemin absolu, et autres métadonnées du fichier. Le composant ne fournissant pas l'option permettant de renvoyer les propriétés de type chemin compatible Linux, nous branchons sa sortie sur l'entrée d'un composant Talend tReplace. Grâce à une expression régulière (regexp), le composant tReplace_1 va nous produire un path absolu compatible linux dans une propriété abs_path qui représente le chemin absolu de la ressource listée.
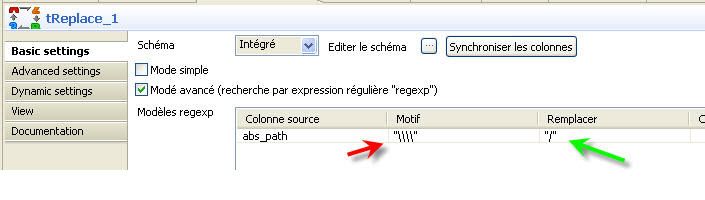
Le traitement se faisant élément par élément, c'est-à-dire dans un flow, il est impératif de collecter tout le résultat. Le composant tFlowToIterate_1 va collecter tous les éléments du flow et les ressortir par itération. Le composant suivant tIterateToFlow_1 va transformer les itérations en flow de données ; ce qui évite des situations où seule la dernière ligne traitée se retrouve sérialisée dans le fichier de sortie.
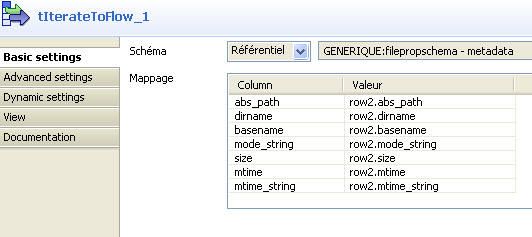
Le composant tMap_1 va faire quelques transformations sur la structure de données entrante (les métadonnées du fichier ou sous-dossier traité) et produire une autre structure prête et facile à persister dans le fichier XML du plan de classement ; autrement dit, le composant est utilisé pour affiner le mapping des propriétés à écrire dans le fichier XML du plan de classement. La figure 20 montre la transformation opérée.
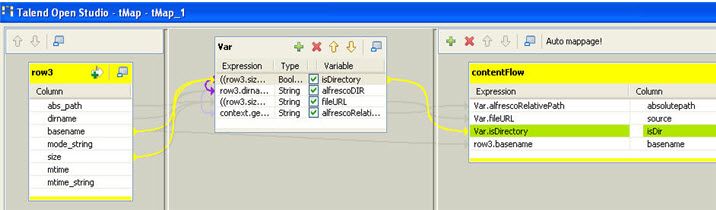
Le dernier composant tAdvancedFileOutputXML_1 enregistre les informations dans le fichier XML du plan de classement.
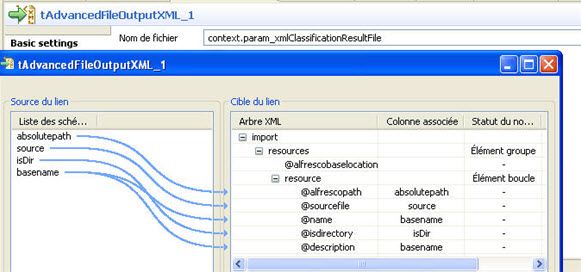
A ce stade, le fichier XML plan de classement est complet. Il décrit totalement les documents à importer et comment ils seront classés dans le référentiel Alfresco. Le Job suivant va prendre ce fichier XML en entrée, établir la connexion avec le serveur Alfresco distant puis envoyer les documents pour stockage.
IV-E-3. Intégration des documents dans Alfresco « Job LoadXMLContentHierarchyIntoAlfresco »▲
Le second Job LoadXMLContentHierarchyIntoAlfresco est basé sur un composant Talend pour Alfresco et a pour principale tâche de se connecter au serveur Alfresco distant, et envoyer les documents suivant le plan de classement défini. Il est lancé à partir du lanceur tRJalfrescoXMLImporter.
Il prend en paramètres les éléments suivants :
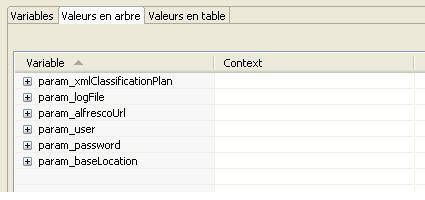
- Param_xmlClassificationPlan : le nom du fichier XML plan de classification à lire ;
- Param_logFile : nom du fichier où seront écrits les logs de l'opération ;
- Param_alfrescoUrl : adresse du serveur Alfresco auquel il va tenter de se connecter ;
- Param_user, param_password : paramètre d'authentification sur le serveur Alfresco ;
- Param_baseLocation : répertoire de base dans Alfresco à l'intérieur duquel le plan de classement sera crée et les documents importés.
Le Design de ce job est relativement simple car ne comporte que deux composants (voir figure 23).

Le job LoadXMLContentHierarchyIntoAlfresco est assez simple et constitué des composants tFileInputXML_1 et tAlfrescoOutput_1. tFileInputXML_1 lit le fichier XML du plan de classement. La figure 24 montre sa configuration.
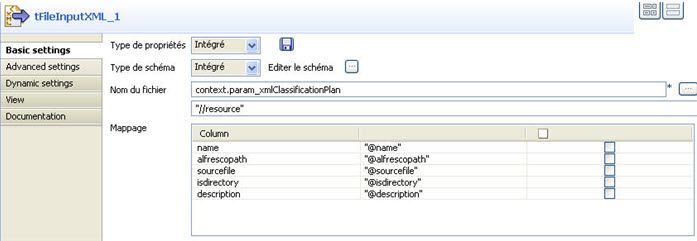
Le composant va créer un flow de données contenant les informations de chaque élément resource du fichier XML (d'où l'expression XPath permettant de retrouver tous ces nœuds : //resource). Pour rappel, une ressource est soit un fichier, soit un sous-dossier du répertoire de documents importés. Le nom du fichier XML à lire est porté par le paramètre d'entrée param_xmlClassificationPlan accessible par la variable contextuelle context.param_xmlClassifictionPlan.
En sortie du tFileInputXML, nous produisons un schéma calqué sur les attributs de l'élément resource et comprenant : nom, chemin relatif dans Alfresco à partir de la base, le fichier source à importer, true ou false selon que la ressource est un dossier ou un fichier, et une description de la ressource.
Le flow de données dirigé sur le dernier composant tAlfrescoOutput_1 dont le rôle final sera de :
- se connecter au serveur distant ;
- envoyer la ressource ;
- faire des logs.
Bien sûr, les informations d'accès et de connexion au serveur doivent lui être fournies. D'où sa configuration figure 25.
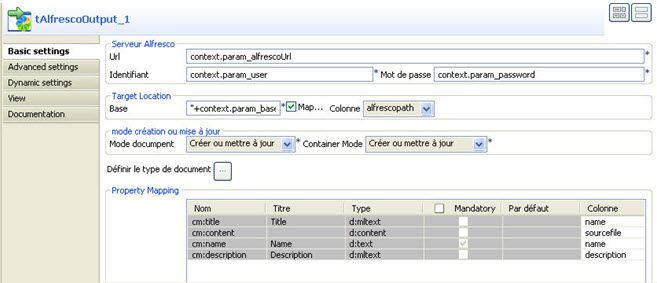
L'URL du serveur est dans context.param_alfrescoUrl ; le login de connexion dans context.param_user et le mot de passe dans context.param_password. Ces trois informations sont suffisantes pour se connecter au serveur distant. Mais pas suffisantes pour réaliser l'opération.
Le Target location permet de spécifier le chemin de base dans l'entrepôt Alfresco où seront rangés les documents importés.
Il est constitué de deux zones de texte :
- Une zone base qui permet de définir la base : "+context.alfrescobaselocation+". Initialement, ce champ n'est pas fait pour contenir des expressions à évaluer mais uniquement une chaîne de caractère String. En utilisateur averti de la manipulation des chaînes de caractère en Java et donc par Talend, nous usons de l'addition pour neutraliser les quotes prévues par Talend dans le code généré, ceci afin d'encapsuler le contenu de ce champ et ainsi forcer l'évaluation du paramètre.
- Une zone pour la spécification de la seconde partie du chemin : ici c'est le chemin relatif porté par la colonne alfrescopath.
La troisième section permet de sélectionner le mode de création (ou de mise à jour) des documents (respectivement nœuds) à importer (respectivement créer).
Dans le repository Alfresco, tout objet doit posséder un modèle. C'est-à-dire, les dossiers sont basés sur un modèle de contenu, les fichiers aussi etc. Le modèle de contenu de base d'Alfresco est défini dans le fichier contentModel.xml. Dans notre cas, nous voulons importer deux types de données : des fichiers et des dossiers. Il va donc falloir préciser au composant tAlfrescoOutput_1 quel modèle de contenu doit être utilisé dans Alfresco pour les fichiers et les dossiers. Et aussi, quelles propriétés doivent être mappées aux propriétés définies dans les modèles. Par défaut, les fichiers seront mappés au type "cm:content" et les dossiers au type "cm:folder" du modèle de base contentModel.xml. Faisons la remarque que nous aurions pu faire mieux , en définissant nos propres modèles de contenu et les utiliser dans le mapping.
Afin de préciser le modèle de contenu à utiliser, il faut double cliquer sur le composant tAlfrescoOutput_1. La fenêtre correspondant à la figure 26 s'ouvre.
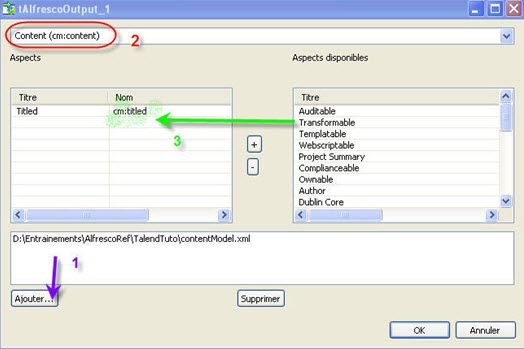
Le type cm:titled sera mappé avec le nom du fichier importé, et cm:content avec le fichier. Les opérations à faire sont les suivantes :
- faire référence au fichier contentModel.xml ;
- sélectionner le modèle de contenu qui convient : cm:content ;
- faire glisser l'aspect Titled vers la liste des aspects à utiliser.